


 Back to Blog
Back to Blog
By Alex Masharov |
March 7, 2024 |
PostgreSQL's real-time Streaming Replication for Disaster Recovery (DR) is an important feature for ensuring the resilience and availability of mission-critical databases. Unlike basic periodic backups, this mode enables continuous and near-instantaneous replication of data from a primary PostgreSQL server to one or more standby servers, in either synchronous or asynchronous modes. This makes it a valuable tool for minimizing downtime and mitigating data loss in the event of unforeseen disasters, hardware failures, or other disruptions. However, despite its advantages, PostgreSQL Streaming Replication isn’t perfect (alas!), and can stumble for a variety of reasons, such as network latency, scalability issues, and environment inter-dependence, among others.
In today’s blog, we will go over the top 4 problems DBAs encounter when using Streaming Replication for DR, and what to do about them.
But first, what is Streaming Replication?
PostgreSQL has two fundamental methods for Disaster Recovery: Archive Mode and Streaming Replication Mode (sometimes called Data Streaming).
Archive Mode writes Write-Ahead Logging (WAL) files, either when a certain number of transactions has occurred, or on a configured time interval. These WAL files can then either be saved as a backup chain and/or periodically transferred to the standby server and applied to the standby cluster to bring it up to date with the primary.
Streaming Replication instead continuously replicates changes from the primary database to the standby server in near real-time, by setting up the standby server to connect to the primary cluster directly using something called a Replication Slot (RS) and essentially opening a data pipe. Every transaction is then pushed down to the standby cluster as soon as it is committed on the primary.
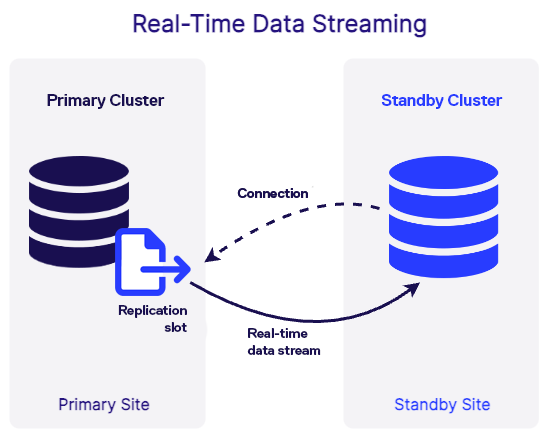
Logical vs Physical Replication
You have probably come across these terms at some point while researching PostgreSQL DR, but what do they mean exactly? Well, Data Streaming can be used with two types of replication: Logical Replication and Physical Replication.
Logical Replication involves replicating changes at the level of database objects, such as tables and rows, by transmitting the actual changes (inserts, updates, deletes) made to the primary database. This approach can be more flexible and granular, allowing for selective replication and supporting replication to different versions of PostgreSQL, however, it can be (and typically is) a technically challenging process to set up correctly for DR purposes.
Physical Replication, on the other hand, replicates the entire cluster from the primary server to the standby servers, making it a better choice for data consistency, as well as being a lot more straightforward.
In this blog, we will be covering Physical Replication only.
Advantages of Streaming Replication
Before we get into the (potential) problems, let’s quickly go over some of the benefits inherent to Streaming Replication DR:
-
Real-Time Sync: Data Streaming replicates nearly in real-time, minimizing data lag between primary and standby servers compared to more traditional backup and restore methods.
-
Quick Resynchronization: If the standby cluster goes out of sync, re-synchronization typically happens automatically (as long as the required WAL records are still available on primary).
-
Better RPO: Since the standby is updated more frequently than it would be with any kind of file-transfer-based replication method, the overall potential maximum data loss is reduced.
Potential problems
Here are the top 4 problems with Streaming Replication (as reported by DBAs), and what you can do to make things right again.
1. Network latency: PostgreSQL Streaming Replication relies on a stable, low-latency network for the timely replication of changes from the primary to standby servers. When this is unavailable, high network latency can lead to delays in replicating changes, causing the standby to fall behind. In scenarios where the primary database is under high load, this propagation delay can mean that the standby falls further and further behind, with new transactions happening on the primary faster than the total throughput of the network to standby. An unstable network, i.e. one that drops the connection between primary and standby intermittently, would have much the same effect.
Solution: The best solution would be to fix the network, but this is typically beyond a DBA’s scope of action. If the network cannot be fixed, perhaps it is possible to work around it: consider alternative service pathways, providers, or cloud regions, and speak with the system administration team regarding separating database and application/user traffic. Finally, if no network improvement is possible, it may be a good move to switch from using Streaming Replication to another method of replication, e.g. Archive Mode WAL Shipping. Learn about setting up Archive Mode WAL Shipping in this blog.

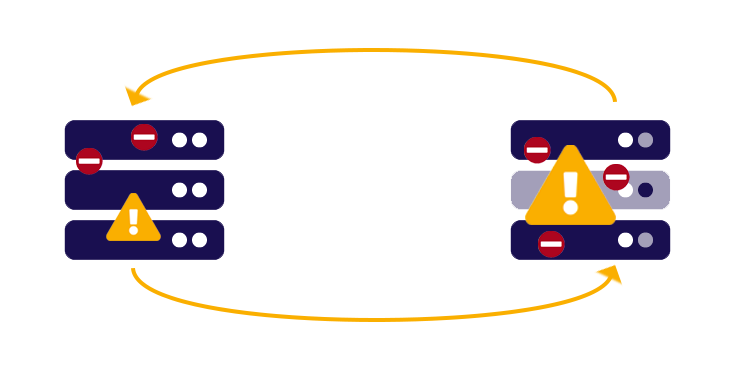
2. Resource intensiveness/environment inter-dependence: If using Streaming Replication in synchronous mode, transactions are not committed on the primary until they are first committed on the standby server. While this synchronous replication ensures strong data consistency by waiting for acknowledgment from the standby before considering a transaction as “successful”, it introduces a significant potential drawback. Any latency or unavailability in the standby servers can impact the primary server's transaction processing, creating a negative interdependence, whereby primary server performance is constrained by the responsiveness of its standby (or standby's).
Solution: Synchronous mode for Streaming Replication is an advanced feature that must be enabled manually, and this is precisely the reason why: if using it, you must ensure that your environments - both primary and standby – are up to the task. If you find that you experience performance bottlenecks, it may be necessary to go back to Asynchronous Streaming Replication.
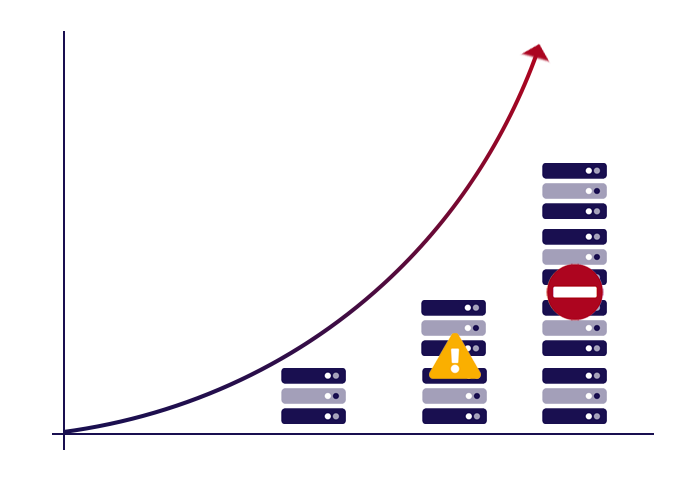
3. Scalability: When a Streaming Replication connection is created from a standby to a primary cluster, it connects into a Replication Slot, which is basically just a record to track the internal database sequence number (called LSN) for transactions sent across to the relevant standby database. When transaction records are sent to standby, this record is updated to track the latest number that has been successfully sent.
If a standby database is not updated for a while (e.g. it is offline), WAL records created after this recorded LSN number are kept on the primary server, waiting for the standby to connect and retrieve them. They are never deleted until this happens, as otherwise when the standby connects and requests data, none would be available to send over (for example, the data could have been written into the database files by then, and the source WAL files recycled by PostgreSQL).
All this means that for every standby database that is not being actively updated, records build up on the primary server disk, potentially indefinitely. Consider now that it is possible to have any number of standbys for a single primary, and you can see there is a big potential problem here: records waiting to be sent over to various standbys can cause the primary to quickly run out of space.
Solution: It is very important to have some kind of replication lag and disk space management tool set up on your primary server - it would be darkly ironic for production to go down due to the disk filling up with data required only by a standby. This is especially critical if you are running multiple standby servers.
Ideally, you should be managing replication lag to all standby environments to ensure WAL files on the primary are always being recycled and do not build up unnecessarily. At the very least, ensure you have disk space monitoring set up so that you can receive an emergency alert that action is required before things go wrong.
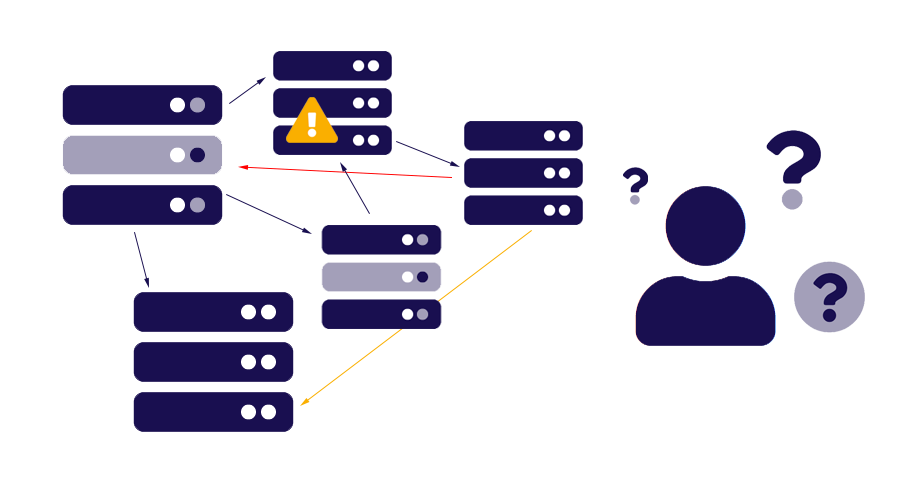
4. DR state confusion/lack of clarity: With no built-in UI or accessible reporting tools, it can be a challenge to get clear information out of PostgreSQL with regard to the current state of a DR replication. Once you have set up Data Streaming, that’s great, but how do you know whether it’s in sync right now? If not, how far behind? What’s the historical trend? How can you get timely alerts in an easy-to-consume format?
DBAs typically get around this by creating sets of custom scripts (which execute command line commands using PostgreSQL utilities) that then collate the information in some way, whether to a basic dashboard or via email notifications. The problem is that such scripts inherently have their own associated set of problems, ranging from creating knowledge silos (typically only the DBA that wrote a particular script has any idea how it works) to introducing new variables into what should be clearly defined Switchover/Failover business processes.
Solution: PostgreSQL Streaming Replication for DR is a great feature with good functionality, but ideally, it needs some kind of tooling on top of it to make up for some of its weaknesses around clarity and UI. Remember that a good DR solution in the real world is much more than just a single tool or feature: it is a process and a way of thinking.
To create good DR habits for business continuity, make sure that you are not only leveraging Data Streaming for PostgreSQL DR, but also fully understand what it’s doing, what to do if an emergency happens, and how to get clear data out to inform your decision-making.
Conclusion
Streaming Replication is the go-to DR solution for PostgreSQL and is generally a great feature that comes highly recommended. The ability to achieve real-time replication, in either synchronous or asynchronous mode, is very helpful in protecting your business from data loss, either on-premises or in the cloud.
Want to see the easiest way to set up Streaming Replication DR? Check out Dbvisit StandbyMP for PostgreSQL for a modern tool with an intuitive, guided UI that makes the whole process a breeze.
It is however important to remember some of the limitations of this replication mode, as well as the associated problems, and have solutions in place before you really need them: disasters usually strike around 3 am on a Sunday morning, and that tends to be too late to write or test failover scripts!
Stay tuned for our next blog where we will provide a high-level comparison of popular DR and HA methods for PostgreSQL!
If you have any questions or would like to organize a POC with one of our technical specialists, contact us today!





