


 Back to Blog
Back to Blog
By Alex Masharov |
December 20, 2023 |
At the PASS Data Community Summit, we spoke with many SQL Server DBAs who shared their experiences and challenges in effectively managing databases, particularly in the realm of Disaster Recovery using Log Shipping or Basic Availability Groups. The insights gathered from these discussions shed light on the complexities that DBAs face in their day-to-day operations. In our upcoming series of blogs, we will address these challenges head-on, how they affect DBAs, and how they can be mitigated with specialized Disaster Recovery software. In this first blog of the series, we are covering the everyday struggles of handling large Log Shipping environments.
What are the current challenges associated with Log Shipping?
While Log Shipping on Microsoft SQL Server is a reasonable basic option for setting up a standby database for Disaster Recovery, this method offers few automation options, is not particularly user-friendly, and can be a challenge to troubleshoot. It also lacks core best-practice DR features, like automated failover, planned switchovers, and easy integration with scripts or APIs.
Dealing with the manual management of multiple large environments, especially in complex Log Shipping setups, is no small feat. Each environment requires its own configuration, schedule, and upkeep, making life complicated for DBAs. Doing this manually not only piles on the workload but also increases the risk of human error. As the number of environments grows, managing them one by one quickly becomes infeasible for a busy DBA. That's why having some automated solutions or centralized management tools becomes invaluable to help streamline and enhance the efficiency of these tasks.
A few specific examples
Managing jobs
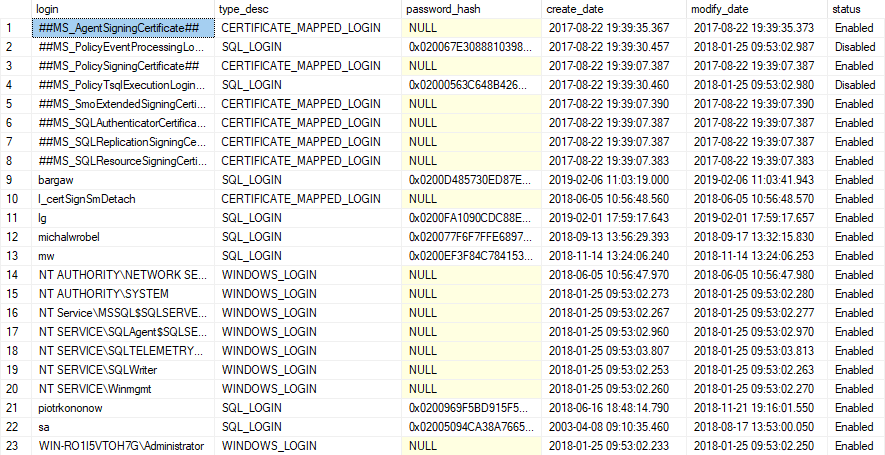
Setting up Log Shipping for a single database involves the creation of 3 separate jobs: a Backup job, a Copy job and a Restore job. These are typically created via the Transaction Log Backup Settings & Secondary Database Settings panels (as well as their relevant sub-panels) in SSMS, or manually scripted in a similar fashion.
Each of these 3 Jobs per database is distinct from each other, i.e. if for some reason the Backup job is postponed/disabled, the other 2 jobs will continue to run (or attempt to, with errors). This means that every time you want to change a DR configuration, you have to manually touch at least 3 separate Jobs - and if you are performing a Switchover, that’s 6 Jobs (to set up log shipping the other way between the new primary to the new standby).
6 Jobs per database x number of databases quickly becomes unmanageable, and any additional scripting done to help with this process becomes yet more “scaffolding” within the company’s DR process that ultimately adds to the technical debt to be managed.
Given that it is not unusual to have upwards of 100 databases within a single SQL Server Instance, any Log Shipping solution must include utilities to configure/handle multiple databases at once.
Monitoring
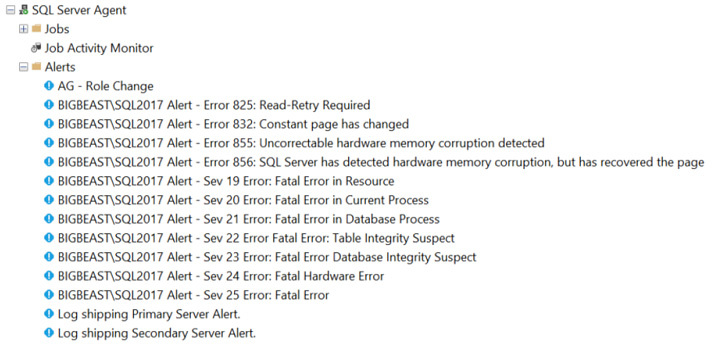
Once you have a DR solution set up, it is critical to keep an eye on it - things usually go wrong when least expected! When setting up Log Shipping, a DBA will typically enable Alerts to be sent to a specified email address when certain things happen, e.g. a log backup file fails to be created or fails to transfer over to the standby system.
When dealing with large numbers of DR configurations, however, it is easy for this simple functionality to become overwhelmed. If you are monitoring a hundred database DR configurations through these basic email alerts, the reality is that some of these configurations will always be in some unexpected state. Perhaps a DBA has manually stopped one from applying a patch, or there is a known fault on a network line: unless each and every email alert notification is manually managed/disabled, these will continually flood the DBA’s inbox and make it very difficult to distinguish real emergency alerts. And, if you do disable them as necessary, you then have to remember to manually turn everything back on later….unless you forget, of course. What then?
It can be very beneficial to introduce a layer of automation between the notifications and the DBA, to classify and potentially filter out alerts from environments in non-standard states for known reasons. The more databases you are managing, the more important this becomes, as otherwise, a DBA can quickly become non-responsive to what is supposed to be an emergency alert channel.
Covering all your (data)bases
How many times has the product team in your organization deployed a new database to production without first telling the DBAs? How can you be certain every production database has an active and updating standby?
The #1 problem of managing a large number of databases is losing track of things: losing track of naming schemes, network addresses, client applications, etc. Within the complexity, something else that often gets lost is whether a database exists at all - the application team may be using it, but the DBAs haven’t been told. Or the other way around: DBAs set up a database based on a requisition order, but the order isn’t tracked by anyone, and the database remains unused.
It is invaluable to have tools in place to track the status of production Instances (and the databases within) and verify that good DR practices are being adhered to for all of them.
A simpler, more modern solution
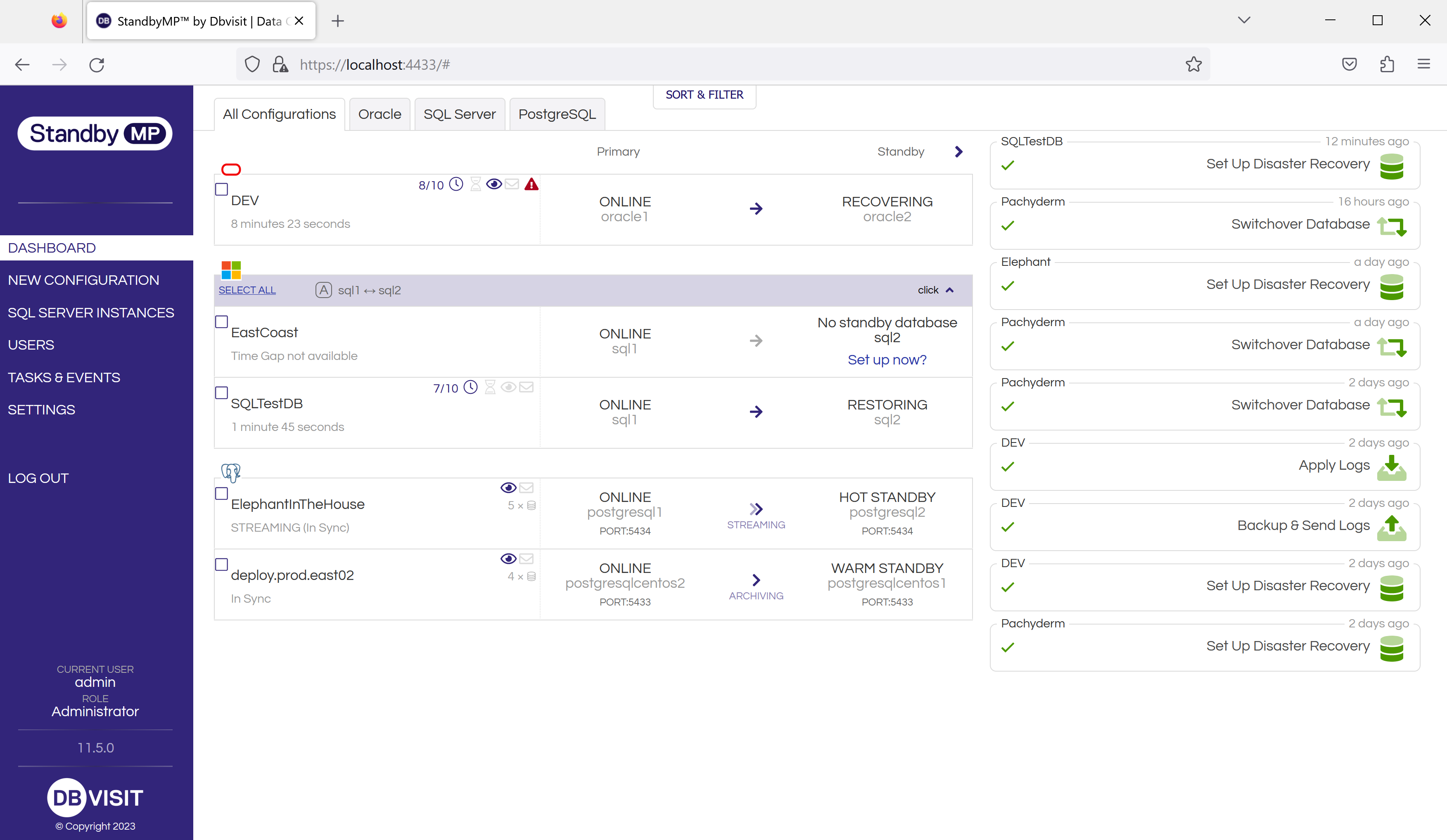
To effectively address the concerns above (and more), consider Dbvisit Standby MultiPlatform. It offers numerous benefits for easily setting up resilient DR on Microsoft SQL Server, simplifying the ongoing management of DR tasks and providing additional core functionality. Both Log Shipping and StandbyMP offer the advantage of easy implementation without additional requirements (such as Windows Server Failover Clustering) and provide support for a broad range of database versions.
StandbyMP provides a unified Control Center to effortlessly create, view, and manage all your Disaster Recovery configurations across multiple Instances. Unlike Log Shipping, where each database must be configured individually, StandbyMP offers the ability to act across any number of databases in parallel. The Control Center not only offers detailed information above what is available from SSMS but also provides practical guidance for speedy troubleshooting, ensuring your databases are consistently safeguarded.
With built-in pre-checks that identify common problems before they have a chance to happen, StandbyMP saves you time and simplifies best-practice actions. Tackle Log Shipping challenges with ease through One-Click Resynchronization, Zero-Data-Loss Switchovers, Automated Standby Creation, and centralized real-time Alerts. Reduce your database management time from hours or days to just minutes.
Stay tuned for our upcoming blog, where we'll explore the next challenge that emerged during the PASS Data Summit – the process of resynchronizing the Log Shipping environment after an irrecoverable gap in the log chain.
Ready to protect your SQL Server databases?
-
Learn more about protecting your critical databases on SQL Server in this technical white paper.
-
You can also take the software for a Test Drive in a two-hour online environment, which only takes two minutes to set up! Try now!
-
Get an instant quote or contact us if you have any questions or would like to organize a demo.


Tags: SQL Server



