


 Back to Blog
Back to Blog
By Tim Marshall |
September 15, 2022 |
One of the most common cloud myths we hear from people thinking about migrating to the cloud is that they don't need Disaster Recovery (DR) because the cloud infrastructure is so reliable. In this blog, we’re going to highlight what we tell all our clients, yes the infrastructure is reliable, but you still need Disaster Recovery for any business-critical database. In fact, most, if not all, Cloud Service Providers (CSPs) recommend having a robust DR solution applicable to your RTO/RPO.
We will go over why the cloud does not imply complete data protection, as well as scenarios where they do go down, such as with Oracle and Google cloud data centres this year. We will then go over why using a warm standby database, either on-premises or in the cloud, is a resilient way to achieve minimal data loss (RPO) and fast recovery (RTO). With increasing threats in today’s digital age, it’s too risky to leave things to chance.
How available is my database in the cloud?
Compared to many organizations traditional on-premise solutions cloud infrastructure may provide a higher uptime and security. However, the cloud is not a failsafe "silver bullet" that eliminates all downtime entirely and reliably. There is a wide variety of potential risks that can cause outages, let’s cover three recent examples experienced by Oracle, Google Cloud, and AWS.
Natural events - extreme weather
In July 2022, Oracle and Google Cloud Data Centres in London went offline as a direct result of the region's worst heatwave recorded. The downtime, caused by cooling system failures, was widespread, taking Virtual Machines (VMs) and Compute offline at all Availability Zones within Google Cloud’s London Region. To learn more about what happened during this incident, visit our cloud outage blog.
Even though Google and Oracle are the world's two most well-known CSPs, an event like this serves as a reminder that cloud services are vulnerable to disruptions that are sometimes beyond anyone's control. This is why we strongly recommend out-of-region disaster recovery so you can avoid localized events.
User error
On February 28th, 2017, a user input error by the Amazon Simple Storage Service (S3) team resulted in the removal of a large number of servers, necessitating full resets of two subsystems. While the S3 APIs were unavailable, other AWS services in the US-EAST-1 Region that rely on S3 for storage, such as the S3 console, Amazon Elastic Compute Cloud (EC2) new instance launches, Amazon Elastic Block Store (EBS) volumes (when data from an S3 snapshot was required), and AWS Lambda, were impacted for up to four hours. A summary of the event can be found here.
Internet backbone issue
Unfortunately, Internet backbone issues, such as DNS outages or submarine cable failures, are common. On June 8th 2022, the Asia-Africa-Europe1 and SeaMeWe5 submarine fibre cables experienced simultaneous cuts limiting internet access to businesses in Africa and Asia. Google Cloud issued a service note stating “Google Cloud Networking experienced increased packet loss for 3 hours and 12 minutes from egress traffic from Google to the Middle East and elevated latency between our Europe and Asia regions”.
The effects of outages and isolated errors can be catastrophic. Such events have the potential to result in the loss of a substantial amount of data, which has enormous repercussions for organisations of all sizes, negatively affecting productivity, reputation, and revenue.
Ask yourself this question: are you able to endure hours without access to a crucial database? It's easy to believe that it will never happen to you, but the examples provided demonstrate that it does happen.
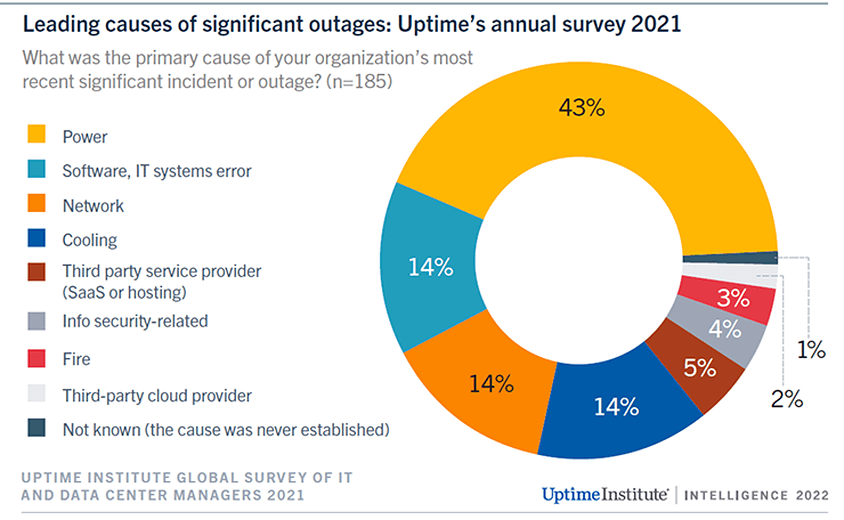 Image source: datacenterfrontier.com
Image source: datacenterfrontier.com
“But my CSP guarantees 99.99% uptime, so this shouldn’t affect me” I hear you say - let’s dig into that misconception a bit more.
What Server uptime do CSPs typically offer?
Most CSPs guarantee 99.99% uptime and will refund a percentage of your monthly service fee, ranging from 10% to 50% if they fail to meet this standard. This is also known as a Service-Level Agreement (SLA). However, this refund pales in comparison to the reputational damage and lost business that could result from an outage. The devil, after all, is in the details. When a CSP guarantees 99.99% uptime, they refer to server uptime rather than database uptime. This is because you are paying for the infrastructure to host your databases, not for the databases themselves. This is primarily due to CSPs' limited control over many aspects of "database accessibility," such as user error, internet outages, performance issues, etc.
As a result, high uptime will not protect you in the event of a disaster. While the server itself may be operational, you will find that your database may be corrupted or unavailable. What's the point of having a server if you can't access your data? This highlights the significance of disaster recovery planning early in the migration process. Let's now look at how you can meet your RTO/RPO requirements.
Implement out-of-region backup and restore
Backups are an important part of any and can be configured in a remote region for databases with a lower RPO/RTO. Whether using the backup functionality built into your database platform or from a third-party vendor, they are cost-effective and help protect against internal actors, data corruption and data loss. The issue is that they are difficult to test, have a poorer RPO/RTO, and can be a target for ransomware.
Implement a standby database
A standby database is a secondary database and complete set of infrastructure located in a remote region that is kept near-synchronized with the primary database. Standby databases are highly resilient and provide a high-performance RPO/RTO that is suitable for business-critical applications. Standby databases created by specialist database software also detect and stop potential corruption, facilitate patching and testing, and enable restoration to specific points in time. Examples include:
-
Oracle Enterprise Edition - Oracle Data Guard / Active Data Guard.
-
Oracle Standard Edition - Dbvisit Standby MultiPlatform.
-
SQL Server Enterprise Edition - Log Shipping, Availability Groups.
-
SQL Server Standard Edition - Log Shipping, Basic Availability Groups, and Dbvisit StandbyMP.
Implement High Availability
You can also implement a high availability technology to complement your Disaster Recovery and offer instantaneous switchovers for minor issues. Oracle RAC, SQL Server Clustering, AWS Multi-AZ and other services can be used to achieve this. A note of caution though - these products are not disaster recovery because (1) They often operate with shared storage creating a single point of failure, (2) They are often synchronous and do not protect bad actors or data corruption, and (3) Usually required to be based in close geographical proximity, providing little protection against region-wide disasters.
Easily respond to the unexpected with StandbyMP
Creating a resilient architecture that protects you against all possible disasters, such as the ones we’ve covered in the blog is essential. Although CSPs typically do not cover these disasters, you can easily build a robust DR solution that covers all disaster types with StandbyMP. Interested in learning more? Read more in our cloud white paper, or feel free to contact us!


Tags: Disaster Recovery, Opinion pieces, Cloud






