 Back to Blog
Back to Blog

Announcing StandbyMP 12.3
StandbyMP 12.3 delivers significant improvements in performance and.


Gain a better understanding of Lost Writes, how to detect them, and how they help keep your primary database free from corruption.

In this blog, I'd like to introduce you to the "Lost Writes" topic. Understanding Lost Writes (and how to detect them) will help you to keep your primary database free from corruption and be aware of possible issues with hardware on the primary server.
One note in the beginning regarding licensing: Lost Write Detection is an Oracle Enterprise Edition feature and should be enabled only on an EE database. On Oracle Database Appliance (ODA) systems this feature is enabled by default and there's no action needed to enable the Lost Write Detection. If you're not sure always consult your local Oracle License Vendor.
A Lost Write is exactly what the name says it is – when a write to disk from the buffer cache is lost. It can happen on any read-write database. When a database block is loaded to the buffer cache and is changed, the database needs to write it back to disk at some point (flushing dirty blocks). The way it's usually done is that this block is handed to the I/O subsystem and the I/O subsystem acknowledges the handover, but the write to disk itself is not done at this point. Database is OK with this acknowledgement and goes on.
After the acknowledgement and before the write happens, an error can occur - and the result is that the write will not happen on the I/O subsystem (it will get lost) and we still have the old block on the disk. But the Database still considers that the write happened. There can be a number of reasons behind this - faulty memory, faulty storage, network issues when using NFS etc.
So in short: the database thinks the block was written to disk, but this in fact didn't happen.
Lost Writes can occur on your production database anytime, because accidents happen. If you have a Standby™️ database, you can easily detect these Lost Writes (but of course it works almost the same way in Dataguard).
You can enable detection very easily. There is not much effort needed to enable that and you will put your standby database to good use even when it's just being synchronized with your primary.
To enable the Lost Write detection on your standby database, set the following parameter on your Primary & Standby database (no restart required):
DB_LOST_WRITE_PROTECT = TYPICAL
This value is fine for the majority of cases. The standby database will now perform a check when applying archived logs.
This parameter will force the primary to write additional information to a redo - specifically SCN of the block which was read from disk, so if your primary has a high amount of redo, you may want to monitor your primary DB performance for a while to ensure this change did not have a negative impact.
When the detection is enabled, your standby database will now report an error when applying an archivelog. Once a Lost Write is detected on the standby, the error will look similar to this:
ORA-00756: recovery detected a lost write of a data block
ORA-10567: Redo is inconsistent with data block (file# 7, block# 3738, file offset is 23429696 bytes)
What happens in the background (how the detection is actually done) is best explained by pictures. To make it more understandable I assigned days of the week for each step to emphasize that the steps do happen with some time delay and also the SCNs and Values are simplified (database blocks usually can contain several rows - not single value)
#1 - The Actual Lost Write on the Primary Database:
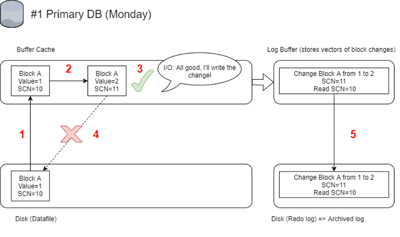
1 - Block is read from disk to buffer cache
2 - Block gets changed from value=1 to value=2 (SCN of the block after change = 11)
3 - IO confirms the change to the database (but the write doesn't happen at this point)
4 - Write gets lost along the way and the change is never written to disk. Block A stays on the disk with value 1 - it's consistent and not corrupted
5 - Together with the change of the block in buffer cache, the change is also written in the redo log file - only the vector of the change is stored (not the actual values) and also read SCN of the block is stored. Once the redo log gets full it will get archived and so this change will be in an archived log which will later be applied to the standby database
#2 - Recovery on the Standby Database (Successful):
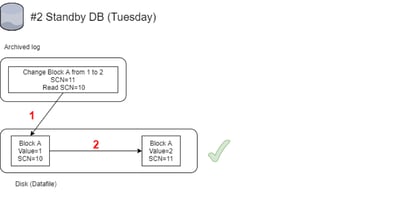
1 - Standby Database block A with SCN=10 and value=1 will get updated while applying archivelog
2 - Vector of change stored in archived log was successfully applied to the block which has changed to value=2 and SCN 11
As you can see at this point, we already have an issue on our primary, but so far all went fine and no error is seen - no error even on the standby database.
#3 - Change of the Same Block on the Primary Database:
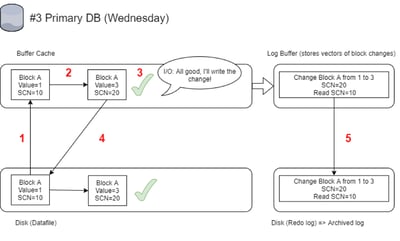
1 - block is read from disk to buffer cache
2 - block gets changed from value=1 to value=3 (SCN of the block after change = 20)
3 - IO confirms the change to the database (but the write doesn't happen at this point)
4 - Write gets successfully done and on disk block A has Value=3 SCN=20
5 - Same as in #1 - Together with the change of the block in buffer cache, the change is also
written in the redo log file - only the vector of the change is stored (not the actual values) and also read SCN of the block is stored. Once the redo log gets full it will get archived and so this change will be in an archived log, which will be later applied to the standby database
This time, everything went fine on the primary - no lost write occurred. The block loaded from disk still has SCN=10 (because the previous write was lost), and the redo will record the database changes block with read SCN=10 - this will later be used by the standby database to detect the lost write.
#4 - Recovery on the Standby Database (Lost Write Detected):
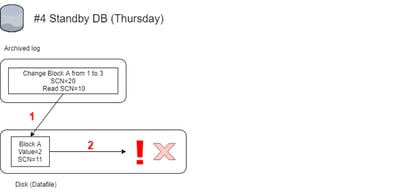
1 - Block with SCN=11 and value=2 will get updated while applying the archivelog. And this is the moment of truth - the standby database will notice a mismatch between existing block in the standby datafile and the change which is supposed to be applied.
2 – During the apply of the archived log, the standby database sees that the expected SCN of the block to be recovered is SCN=10. But on the disk we have SCN=11. And also the vector of the change is different - the vector in archlog is 1=>3 while we have value=2 on the disk. This results in an error:
ORA-00756: recovery detected a lost write of a data block
ORA-10567: Redo is inconsistent with data block (file# 7, block# 3738, file offset is 23429696 bytes)
A Lost Write is detected! The SCN is checked when the block is recovered and when looking at the standby alert log we can indeed see the standby reports a mismatch:
The standby redo application has detected that the primary database lost a disk write.
No redo at or after SCN 0x000000000316dd1a can be used for recovery.
BLOCK THAT LOST WRITE 129, FILE 5, TABLESPACE# 18
The block read during the normal successful database operation had SCN 51829907 (0x000000000316dc93) seq 5 (0x05)
ERROR: ORA-00752 detected lost write on primary
Recovery interrupted!
If someone is not familiar with lost writes, then the instinctive reaction after seeing this error on a standby database when recovering is to delete the standby database and re-create it. Because the error occurred on the standby, it's the standby that is corrupted, right? Wrong!
Never re-create or SYNC your standby database after you see lost writes without considering the consequences first!
The database which has the corruption is actually the primary database – the standby database is without any corruption and it would be a mistake to delete it (or synchronize it) as it's your only non-corrupted database at the moment.
The recommended way would be to activate the standby database and start using it as a new primary. But is this approach really viable? If we think about real-life situations: there is a delay between the time when an archivelog is generated on the primary and when an archivelog is applied to the standby (not to mention the delay until a DBA notices something went wrong with the recovery on the standby database).
Once you see the lost write error, your primary database will probably already be some minutes ahead and if you would activate the standby database you would have data loss, because the standby can't be recovered beyond the change where the lost write was detected. Also, what if the corrupted block on the primary belongs to some insignificant table or index - does it really make sense to activate the standby database then?
As always, everything depends on the particular situation you find yourself in. The reasonable approach once a lost write is detected is the following
It is a good idea to enable lost writes detection on your standby database. There's no additional "cost" and this way your otherwise idle standby database can serve yet another purpose. Even if it seems that you have very limited options on how to recover from lost writes (in most cases you probably simply ignore it), it makes sense to check for lost writes.
Detecting lost writes serves as an "early warning" to signal that there is something awry going on with your primary database, for example, a dying disk. Detecting lost writes is a proactive step to add to a DBA’s daily work and I strongly recommend that you use it.
Finally, here are Oracle MOS notes which you can check for more information about this topic:
ORA-600 [3020] "Stuck Recovery" (Doc ID 30866.1)
Resolving ORA-752 or ORA-600 [3020] During Standby Recovery (Doc ID 1265884.1)
Lost writes can be a complex issue to resolve and there can be cases when reported lost writes are false positives, so it is always recommended to contact MOS when dealing with lost writes.





