


 Back to Blog
Back to Blog
IT management and executives understand the importance of a robust Disaster Recovery (DR) plan, yet often underestimate the levels of complexity and ongoing time that it takes DBAs to set up and maintain traditional DR solutions. SPOILER – it doesn’t have to be this way.
Typically, I see two scenarios:
(1) Businesses who are ignoring DR, or to be more kind, are unaware of the lack of protection that their DR processes offer.
(2) Those who believe their DIY solutions are good enough to get by. Unfortunately, the reality is that a database failure is binary, and there is no participation certificate for almost getting it right.
Microsoft SQL Server offers a range of free tools that, if properly implemented and carefully maintained, can offer basic protection. However, the level of protection realized will vary dramatically depending on the SQL Server license type, the implementation method, and the ongoing diligence applied to monitoring, maintaining and testing. In short, setting up effective DR can be difficult, prone to human error, and time-consuming to both create and maintain.
To help DBAs address these challenges here are five reasons why every SQL Server DBA should evaluate Dbvisit Standby MultiPlatform (StandbyMP).
Facilitating Disaster Recovery best practices
Critical database failure is a predictable reality. Without specialist DR software it's hard and time-consuming to run regular DR tests and implement security patches, to establish your incident readiness.
As a DBA, you need to be 100% confident that your DR strategy will work flawlessly during a major incident. This means having tested, verified and easy-to-follow failover processes.
-
StandbyMP empowers DR excellence: Swift one-click maneuvers for routine DR operations.
-
Simplify regular DR evaluations: Streamline DR testing effortlessly. Activate read-only mode in one click, and conduct comprehensive DR assessments via one-click Graceful Switchovers (meticulously planned, data-intact transitions to standby site).
-
Enhance patching frequency sans downtime: Augmented safeguarding, coupled with highly automated Graceful Switchovers, accelerates and amplifies patching frequency, eliminating the intricacies of process upkeep.
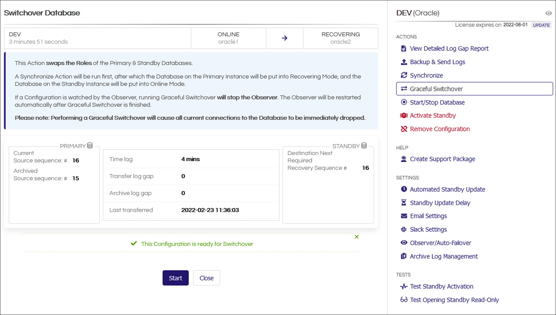
Taking the stress out of database failovers
As a DBA, the pressure of a major incident is never welcome. The last thing you want to be doing is unpicking a previous DBA’s solution and scripts, or manually rebuilding a database. StandbyMP can simplify DR processes by standardising the setup and management. In addition, automated failover massively simplifies the recovery process.
Scaling up, the failover process can be performed simultaneously on as many databases as you want and a full failover can be completed in just a few minutes.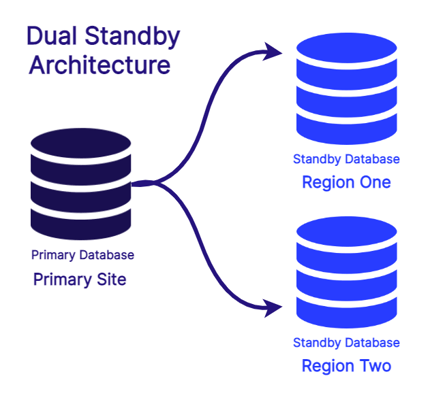
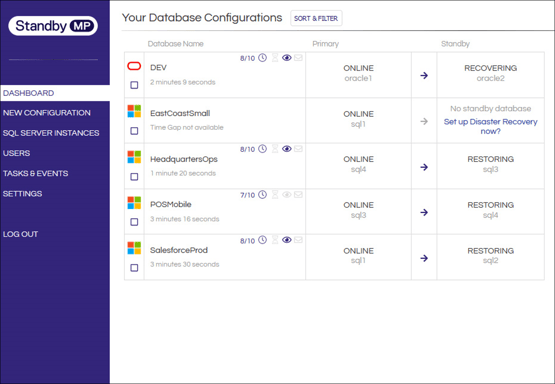
Simplify and speed up workflows
Everyone is being asked to do more with less, and none of us (DBAs included) have the time to constantly test manual recovery procedures and scripts across many databases and instances. Managing multiple Basic Availability Groups for many different databases, along with a smattering of Log Shipping Standby databases is not sustainable or scalable.
However, there is a better way, rather than working with multiple tools and individual databases, StandbyMP enables you to view and manage all your DR configurations from one central console. While having visibility of all your configurations in one console is powerful on its own, you can go further, simplifying complicated procedures with one-click actions, and form tasks simultaneously with multi-database actions.
Maximize resilience to all disasters
Achieving a fully resilient standby database that meets an organization's RPO and RTO requirements is difficult to achieve on SQL Server Standard Edition.StandbyMP has a low bandwidth architecture, dual-standby capability, and customizable log-gap delay. This means your organisation can achieve its RPO and RTO requirements for all disaster scenarios.
If required, you can go further easily setting up two standby databases in different geographic locations, with one running on a time delay to deliver even greater production against ransomware and internal actor scenarios.
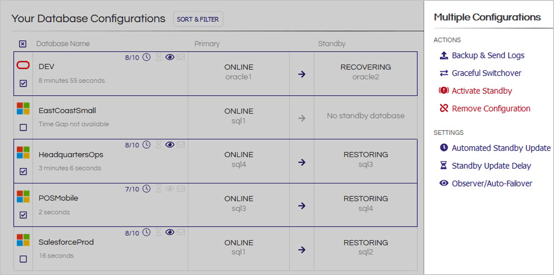
Disaster Recovery does not have to be hard or expensive
A significant barrier for a lot of organizations is the fear that overhauling critical processes such as DR will be complicated and/or expensive. There is no need for a big architectural project. StandbyMP works with your current environment with no additional prerequisites, and is easy to install, meaning that you could have DR sorted in an hour!
Compare this to Basic Availability Groups that require WSFC configuration on each node, setup of correct users and permissions across servers, and creation of individual AGs for each database.
DBAs deserve to be able to take a holiday or a day off for their birthday without being interrupted. By replacing complex bespoke processes with standardized and intuitive DR, DBAs can work collaboratively on database continuity.
Interested in learning more?
Find out more about how StandbyMP can improve your DR processes and go beyond Basic Availability Groups and Log Shipping in our white paper.
If you have any questions or would like to discuss how Dbvisit StandbyMP could fit within your organizational needs, contact us, and one of our technical specialists will reach out to you.


Tags: database failover, Data integrity, SQLserver


